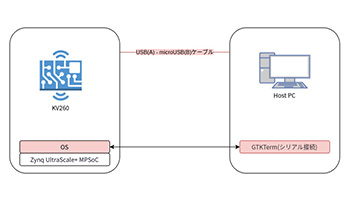
Kria Starter Kitで、Vitis AIを動かす
コンパイル済みAIモデルのデバッグ
公開日:2023年7月31日
本記事では、Xilinxのツールを使用して、コンパイル前後のAIモデルの入出力データを比較、デバッグする方法を確認します。
デバッグ方法の情報は Xilinxの資料 を確認してください。
デバッグにより、コンパイルで推論結果に違いが出るケースで、どのオペレータに問題があるのかを追求することが可能になります。
目次
使用するモデル
AI推論の精度比較 の成果物を使用します。
| ファイル名 | 内容 |
|---|---|
| my_mnist_2_q.h5 | コンパイル前(量子化済み)AIモデル |
| my_mnist_2_q.xmodel | KV260用AIモデル |
使用する環境
Vitis-AI開発環境で conda activate vitis-ai-tensorflow2 を実行、Tensorflow2環境を有効化しておいてください。
本記事でのVitis-AI開発環境は、このTensorflow2環境を意味します。
コンパイル前AIモデルの構成
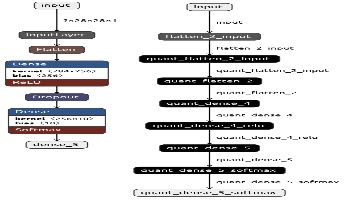
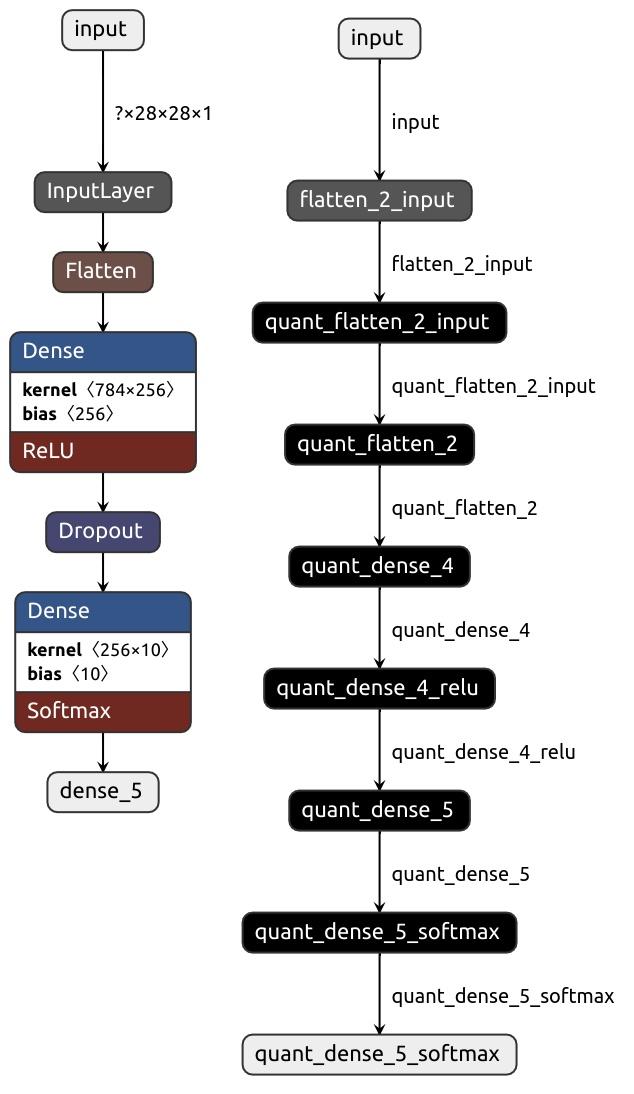
Netron を使ってオリジナルと量子化後のAIモデルの、my_mnist_2.h5 と my_mnist_2_q.h5 を表示してみます。
Netronを起動、AIモデルファイルを選択することで表示されます。
左がオリジナルで、右が量子化後のAIモデルとなります。
Vitis-AIによる量子化が行われていることが分かると思います。
コンパイル済みAIモデルの構成
xdputil コマンドでコンパイル済みAIモデルの情報を出力することができます。
ホストPCでVitis-AI開発環境のまま、以下で情報出力を行います。
AIモデルの構成図を出力します。
全体構成が確認できます。
xdputil xmodel --png my_mnist_2_q_xmodel.png ./output_my_mnist_xmodel/my_mnist_2_q.xmodel
AIモデルの構成図(クリックで拡大)
次に subgraph のリストを出力します。
indexの値はデバッグ時に使用します。
また、deviceの情報でCPU or DPUのどちらで実行されるのかも確認できます。
xdputil xmodel -l ./output_my_mnist_xmodel/my_mnist_2_q.xmodel{
"subgraphs":[
{
"index":0,
"name":"subgraph_flatten_2_input",
"device":"USER"
},
{
"index":1,
"name":"subgraph_quant_flatten_2_fix_reshaped",
"device":"CPU"
},
{
"index":2,
"name":"subgraph_quant_dense_4(TransferMatMulToConv2d)",
"device":"DPU",
"fingerprint":"0x101000016010407",
"DPU Arch":"DPUCZDX8G_ISA1_B4096",
"workload":406794,
"input_tensor":[
{
"index":0,
"name":"quant_flatten_2_fix_reshaped_inserted_fix_1",
"shape":[
1,
4,
14,
14
],
"fixpos":6
}
],
"output_tensor":[
{
"index":0,
"name":"quant_dense_5_softmax_fix",
"shape":[
1,
10
],
"fixpos":1
}
],
"reg info":[
{
"name":"REG_0",
"context type":"CONST",
"size":203530
},
{
"name":"REG_1",
"context type":"WORKSPACE",
"size":256
},
{
"name":"REG_2",
"context type":"DATA_LOCAL_INPUT",
"size":784
},
{
"name":"REG_3",
"context type":"DATA_LOCAL_OUTPUT",
"size":16
}
]
},
{
"index":3,
"name":"subgraph_quant_dense_5_softmax",
"device":"CPU"
}
]
}リファレンスデータ生成
コンパイル前AIモデルで、一つのテストデータに対する出力結果を、リファレンスデータとして生成します。
Vitis-AI開発環境で vitis_quantize.VitisQuantizer のdump_model関数を使用することで生成できます。
以下コードで reference_data ディレクトリに保存します。
一つのテストデータは、MNISTのテストデータの最初のデータを使用しています。
import tensorflow as tf
from tensorflow.keras.models import load_model
from tensorflow_model_optimization.quantization.keras import vitis_quantize
# quantized model
QUANTIZED_MODEL_FILE = "./output_my_mnist_2/my_mnist_2_q.h5"
# output dir
OUTPUT_DIR = "./reference_data"
# load dataset
(x_train, y_train),(x_test, y_test) = tf.keras.datasets.mnist.load_data()
# normalization
x_train = x_train/255.0
x_test = x_test/255.0
# load quantized model
quantized_model = tf.keras.models.load_model(QUANTIZED_MODEL_FILE)
# create reference data
vitis_quantize.VitisQuantizer.dump_model(model=quantized_model, dataset=x_test[0:1], output_dir=OUTPUT_DIR, dump_float=True)reference_data 以下に dump_results_0 と dump_results_weights が作成され、そのディレクトリ以下に入出力データと重みのデータが保存されます。
コンパイル済みAIモデルの出力データ確認
KV260環境に移動して、コンパイル済みAIモデルのデバッグを行います。
KV260の /home/petalinux 以下に debug_ai_model という作業ディレクトリを作成します。
作業ディレクトリにリファレンスデータと my_mnist_2_q.xmodel を配置します。
KV260に接続して作業ディレクトリに移動します。
Xilinxの資料 の手順通りにデバッグできなかったため、subgraph毎にデバッグ実行して確認します。
まず、以下コマンドを実行しておきます。
env XLNX_ENABLE_DUMP=1 XLNX_ENABLE_DEBUG_MODE=1 XLNX_GOLDEN_DIR=./reference_data/dump_results_0次に、 xdputil run コマンドを使用してsubgraph毎にデバッグを実行します。
使用方法は以下です。
xdputil run -i [subgraphのindex番号] [xmodelのパス] [subgraphへの入力データ]
subgraphのindexは コンパイル済みAIモデルの構成 で確認できます。
実行すると、subgraph単位の出力結果が 0.xxx.bin の形で保存されます。
この出力結果を次のsubgraphに渡していくことで、subgraph単位の比較が可能です。
subgraph0 は USER なのでsubgraph1-3をデバッグします。
リファレンスデータの ./reference_data/dump_results_0/quant_flatten_2_input.bin が subgraph1 への入力データです。この入力データは、コンパイル前のAIモデルに入力したデータと同じですので、出力結果も同じであることが期待値となります。
xdputil run -i 1 my_mnist_2_q.xmodel ./reference_data/dump_results_0/quant_flatten_2_input.bin0.quant_flatten_2_fix_reshaped_inserted_fix_1.bin が出力されるので、次のsubgraphの入力とします。
xdputil run -i 2 my_mnist_2_q.xmodel 0.quant_flatten_2_fix_reshaped_inserted_fix_1.bin0.quant_dense_5_softmax_fix.bin が出力されますので最後のsubgraphの入力とします。
xdputil run -i 3 my_mnist_2_q.xmodel 0.quant_dense_5_softmax_fix.bin最終出力データの 0.quant_dense_5_softmax.bin が得られます。
結果の比較
reference_data/dump_results_0/quant_dense_5_softmax_float.bin がコンパイル前の最終出力データ、0.quant_dense_5_softmax.bin がコンパイル後の最終出力データとなります。
この2ファイルを比較します。
比較はツールのコマンドで実行可能です。
xdputil comp_float [リファレンスデータのファイル] [KV260でダンプしたファイル] [-t threshold]threshold は相対誤差のしきい値でデフォルトで0.01(1%)となっています。
以下を実行して比較します。
実行はホストPCのVitis-AI開発環境でも、KV260でもどちらでも良いです。
xdputil comp_float reference_data/dump_results_0/quant_dense_5_softmax_float.bin 0.quant_dense_5_softmax.bin以下結果となり、最終出力データは一致していることが分かりました。
float bin file comparison done.
golden file and dump file are the same!threshold を0として完全一致しているか確認してみます。
xdputil comp_float reference_data/dump_results_0/quant_dense_5_softmax_float.bin 0.quant_dense_5_softmax.bin -t 0以下結果となり、完全一致はしていませんでした。
float bin file comparison done.
golden file and dump file are different!上記からコンパイル前後のAIモデルの最終出力は、完全一致していないものの、相対誤差1%以内に収まっているということが分かりました。
オペレータ単位のデバッグ
subgraph単位でデバッグしましたが、オペレータ単位でデバッグすることも可能です。
xdputil run_op [-r REF_DIR] [-d DUMP_DIR] [xmodelパス] [オペレータ名]REF_DIR, DUMP_DIR はデフォルトで ref, dump となります。
オペレータ名は コンパイル済みAIモデルの構成 の Name を指定します。
入力データが必要なオペレータは ref ディレクトリにTensor名.binの名前で事前にデータ配置しておく必要があります。
実行すると dump ディレクトリにTensor名.binの名前で出力されますので内容を確認します。
dumpに出力されたデータは、次のオペレータの入力として、refにコピーすれば次のオペレータのデバッグを行うことができます。
本記事の場合、refディレクトリを作成し、最初の入力を quant_flatten_2_input.bin として配置します。
mkdir ref
cp ./reference_data/dump_results_0/quant_flatten_2_input.bin ref
以下のスクリプトを実行し、各オペレータの出力をダンプします。
operator_names=(
"quant_flatten_2_fix_reshaped"
"quant_flatten_2_fix_reshaped_upload_0"
"quant_dense_4_bias_new"
"quant_dense_4_const_const(reshaped)_new"
"quant_dense_4(TransferMatMulToConv2d)"
"quant_dense_5_bias_new"
"quant_dense_5_const_const(reshaped)_new"
"quant_dense_5(TransferMatMulToConv2d)"
"quant_dense_5(TransferMatMulToConv2d)_inserted_fix_4_reshaped"
"quant_dense_5(TransferMatMulToConv2d)_inserted_fix_4_reshaped_download_0"
"quant_dense_5_softmax_fix_quant_dense_5_softmax"
"quant_dense_5_softmax"
)
for operator_name in "${operator_names[@]}" ; do
xdputil run_op my_mnist_2_q.xmodel ${operator_name}
rsync -a dump/ ref/
donedumpディレクトリに各オペレータの出力結果が配置されます。
対応するリファレンスデータと比較することで中間の層のデバッグを行うことができます。
まとめ
コンパイル済みAIモデルのデバッグ方法を確認しました。
コンパイル前後で出力結果が変化している場合、どこのオペレータに原因があるのかデバッグする方法があることが分かったと思います。
※文中に記載されている各種名称、会社名、商品名などは各社の商標もしくは登録商標です。